{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




Probably the most important thing to remember about the World Wide Web and the Internet in general is that they are global in scale and often a very cooperative venture. Information on the Web tends to be distributed around the world, and it's just as easy for you to access a site in New Zealand or Japan as it is to access Web information in your own state.
The basic reason for learning HTML is to create pages for the World Wide Web. Before you start, though, you'll want to know a little about how this whole process works. We'll begin by taking a look at Web browsing programs, then we'll talk about how the World Wide Web works, and we'll discuss some of the terms associated with surfing the Web. Finally, we'll round out the discussion by talking about the Internet in general and the different services available on the Internet and how they interact with the Web.
The World Wide Web is an Internet service, based on a common set
of protocols, which allows a particularly configured server computer
to distribute documents across the Internet in a standard way.
This Web standard allows programs on many different computer platforms
(such as UNIX, Windows 95, and the Mac OS) to properly format
and display the information served. These programs are called
Web browsers.
| Note |
Notice that the Web is composed of different sites around the world. A site is basically just a collection of HTML documents that you can access with your Web browser. HTML documents offered for viewing by Que Corporation (http://www.mcp.com/que), for instance, are organized in a site. I personally have created a Web site that people can visit to read about me, my books, and writing services. |
The Web is fairly unique among Internet services (which include Internet e-mail, Gopher, and FTP) in that its protocols allow for the Web server to send information of many different types (text, sound, graphics), as well as offer access to those other Internet services. Most Web browsers are just as capable of displaying UseNet newsgroup messages and Gopher sites as they are able to display Web pages written in HTML (see fig. 2.1).
Figure 2.1 : Here's a Gopher site as displayed through Netscape Navigalor.
This flexibility is part of what has fueled the success and popularity
of the Web. Not only do the Web protocols allow more interactive,
multimedia presentations of information, but the typical Web browser
can also offer its user access to other Internet resources, making
a Web browser perhaps a user's most valuable Internet application.
| How the World Wide Web Began |
The Web protocols were first created by Tim Berners-Lee when he was with the European Laboratory for Particle Physics (also know as CERN). His initial goal was to allow other physics groups and labs to collaborate over the Internet, but others soon began implementing the protocols for their own uses. Mosaic, the first graphical browser for the Web, appeared in 1993, at a time when there were not many more than 50 HTTP (Web) server computers running in the world. The arrival of Mosaic and similar browsers caused an explosion in the popularity of the Web (and arguably, of the entire Internet) because of their ability to display graphics and other multimedia elements. Within nine months, the number of Web servers had jumped to over 300. In 1994, the World Wide Web Consortium (W3C) was formed by interested corporate and educational entities to combine their resources and continue creating standards for the Web. The W3C continues to be largely responsible for negotiating standards and creating technology to enhance data transfer on the Web. |
Unlike any other Internet service or protocol, the World Wide Web is based on a concept of information retrieval called hypertext. In a hypertext document, certain words within the text are marked as links to other areas of the current document or to other documents (see fig. 2.2). The basic Windows help engine (and many other online help programs) uses this same hypertext concept to distribute information.
Figure 2.2 : Typical hypertext links in a Web document.
As you can see in the figure, links can be text or graphics. The
user moves to a related area by moving his or her mouse pointer
to the link and clicking once with the mouse button. This generally
causes the current Web document to be erased from the browser's
window, and a new document is loaded in its place.
| Note |
Links can point to another part of the same document, in which case clicking the link will cause the browser to move to a new part of the currently displayed document. |
Consider then, that this hypertext concept will affect the way that information is presented and read on the Web. A normal printed book (like this one) presents its information in a very linear way. Hypertext, on the other hand, is a little more synergistic.
On the World Wide Web, this synergy can be taken to an extreme. For instance, you might use hypertext to define a word within a sentence. If I see the following example on a Web page:
The majority of dinosaurs found in this region were herbivores, and surprisingly docile.
then I can assume that the word herbivores is a hypertext link. That link might take me to a definition of the word herbivore that this particular author has provided for his readers. This link might also take me to a completely different Web site, written by another person or group altogether. It might take me to a recent university study about herbivores in general, for instance, or a drawing of a plant-eating dinosaur done by a ten-year-old student in Australia.
For just a moment, imagine you're reading a hypertext document instead of a printed page.
If, for instance you were reading a Web page about my personal hobbies, you'd find that one of the things that interests me most is private airplanes. Clicking that link might take you to a new Web site dedicated to the discussion of personal aircraft, including a link to Cessna Aircraft's Web site. Once there, you could read about Cessna's particular offerings, prices, and perhaps a testimonial offered by a recent satisfied customer. Clicking this link whisks you away to that customer's personal Web site, where you read his accolades for Cessna, and then notice he's a professor at Yale, and has provided a link for more information. Clicking the Yale link takes you to the university's Web site, where you can see different sorts of information about registration, classes, research projects, alumni, faculty, and other interesting tidbits.
This offers important implications for HTML writers. For one, you've got to take into consideration this particular style of presenting information. Also, building a good Web site often means being aware of other offerings on the Web, and creating links to other people's pages that coincide with or expand upon the information you're presenting.
The World Wide Web is composed of millions of Web pages, each of which is served to a browser (when requested) one page at a time. A Web page is generally a single HTML document, which might include text, graphics, sound files, and hypertext links. Each HTML document you create is a single Web page, regardless of the length of the document or the amount of information included (see fig. 2.3).
Figure 2.3 : A typical Web page as viewed through Netscape Navigator.
The Web page in figure 2.3, for example, contains more information
than can be shown on the screen at one time, but scrolling
down the page (by clicking the scroll bar to the right of
the browser window) reveals the rest of that particular Web document-note,
though, that scrolling doesn't present you with a new Web page.
| Tip |
Most browser programs have a text box at the top of the screen that tells you the name of the HTML document being displayed. HTML document names will end with the extension .HTM or .HTML. |
A Web site, then, is a collection of Web pages under the control of a particular person or group. Generally, a Web site offers a certain amount of organization of its internal information. You might start with an index or default page for a Web site, and then use hypertext links to access more detailed information. Another page within the Web site may offer links to other interesting sites on the Web, information about the organization, or just about anything else.
Web site organization is an important consideration for any HTML designer, including those designing and building corporate Web sites. The typical corporate Web site needs to offer a number of different types of information, each of which might merit its own Web page or pages.
The typical corporate Web site will start with an index page that quickly introduces users to the information the site has to offer. Perhaps index is a misnomer, as this page will usually act as a sort of table of contents for the Web site (see fig. 2.4).
Figure 2.4 : This corporate index page others links to different parts of the Web site.
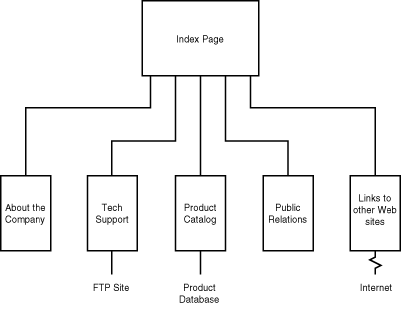
The rest of the pages within a hypothetical corporate Web site will be accessed from a similar index page, allowing users to move directly to the information they want. If users are interested in getting phone numbers and addresses for a company, for instance, they might click a link that takes them to an About the Company page. If they're interested in the company's products, they'd click another link that would take them to a product demo page (see fig. 2.5).
Figure 2.5 : Organizational chart for a basic corporate Web site.
By organizing the site in this way, the designer makes sure that
users can get to every Web page that's part of the site, while
allowing them to go directly to the pages that interest them most.
| Intranets vs. the Internet |
Another use of HTML and Web technology worth talking about is the growing popularity of intranets, or Internet-like networks within companies. In the Web organizational chart discussed in this section, notice that most of the information presented is geared toward the external users. This same technology can be applied to Web sites for internal uses, allowing employees to access often used forms, company news, announcements, and clarifications. For instance, the Human Resources department might make available job listings and addresses on the Internet, but would discuss changes to the company's health insurance policies on their intranet. In fact, many companies are even using HTML to create "front ends" to corporate databases and other shared resources. Using a Web browser application, employees can access data stored on the company's internal network. This takes some programming expertise (usually using CGI-BIN scripts, discussed in this book), but the majority of the work is done in HTML. Fortunately, designing intranet sites and Internet sites isn't overwhelmingly different. The skills you'll gain in this text will be equally applicable to both. The only real difference is a question of organization and the type of information you'll want to offer on your intranet-generally, it's the sort of thing that's not for public consumption. |
With graphical browsers such as NCSA Mosaic and Netscape Navigator, the hypertext concept of the Web was introduced to the world of multimedia, resulting in the hypermedia links that are possible in HTML.
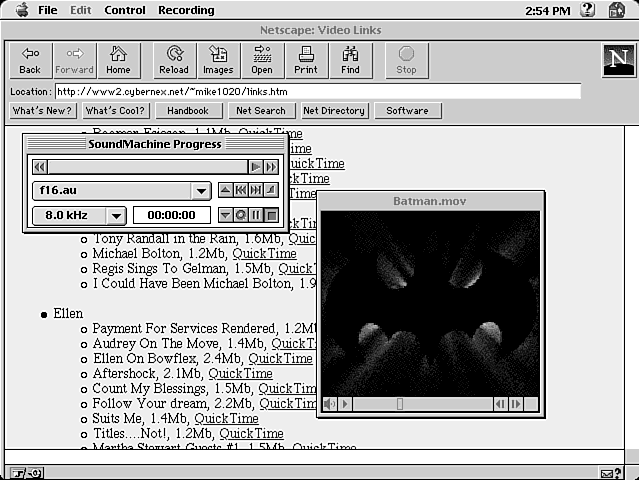
Now, this really isn't much different from the hypertext links we talked about in the previous section-the only difference is that hypermedia links point to files other than HTML documents. For instance, a hypermedia link might point to an audio file, a QuickTime movie file, or a graphic file such as a GIF- or JPEG-format graphic (see fig. 2.6).
Figure 2.6 : Hypemedia links are simply hypertext links that lead to non-HTML documents.
| Tip |
A hypermedia link can be identified by the fact that the associated file has something other than an .HTM or .HTML extension. |
Because of the flexibility of the Web protocol, these files can be sent by a Web server just as easily as can an HTML document. All you need to do is create the link to a multimedia file. When users click that link, the multimedia file will be sent over the Web to their browser programs.
Once the multimedia file is received by the user's Web browser, it's up to the browser to decide how to display or use that multimedia file. Some browsers have certain abilities built in-especially the basics, such as displaying graphics files or plain ASCII text files. At other times, browsers will employ the services of a helper application (see fig. 2.7).
Figure 2.7 : Examples of Web browser helper applications.
Most of these helper applications will be add-on programs that are available as commercial or shareware applications. The browser will generally need to be configured to recognize particular types of multimedia files, which, in turn, will cause the browser to load the appropriate helper application. Once loaded, the downloaded multimedia file will be fed to the helper applications, which can then play or display the multimedia file.
Although it seems that multimedia formats are constantly being
added and improved for the Web, some of the more common types
of multimedia files are listed in Table 2.1 with their associated
file extensions. This list isn't exhaustive, but it should give
you an idea of the types of files that can be distributed on the
Web.
| File Format | Type of File | Extension |
| Sun Systems sound | audio | .au |
| Windows sound | audio | .wav |
| Audio Interchange | audio | .aiff, .aifc |
| MPEG audio | audio | .mpg, .mpeg |
| SoundBlaster VOiCe | audio | .voc |
| RealAudio | audio | .ra, .ram |
| CompuServe GIF | graphics | .gif |
| JPEG (compressed) | graphics | .jpg, .jpeg |
| TIFF | graphics | .tif, .tiff |
| Windows Bitmap | graphics | .bmp |
| Apple Picture | graphics | .pict |
| Fractal Animations | animation | .fli, .flc |
| VRML | 3D world animation | .wrl |
| MPEG video | video | .mpg, .mpeg |
| QuickTime | video | .mov, .moov, .qt |
| Video For Windows | video | .avi |
| Macromedia Shockwave | multimedia presentation | .dcr |
| ASCII text | plain text | .txt, .text |
| Postscript | formatted text | .ps |
| Adobe Acrobat | formatted text |
Not all of these different file formats necessarily require a special helper application. Many sound helpers will play the majority of different sound files, for instance, and some graphics programs can handle multiple file types. For the most part, you will need different helper applications for the various video, animation, and formatted text file types.
Aside from being hypertext-based and capable of transferring a number of multimedia file formats, the Web is unique in its ability to access other Internet services. Being the youngest of the Internet services, the Web can access all of its older siblings, including Internet e-mail, UseNet newsgroups, Gopher servers, and FTP servers. Before we can access these services, though, we need to know what they do and how their addressing schemes work.
Internet e-mail is designed for the transmission of ASCII text messages from one Internet user to another, specified user. Like mail delivered by the U.S. Post Office, Internet e-mail allows you to address your messages to a particular person. When sent, it eventually arrives in that person's e-mail box (generally an Internet-connected computer where he or she has an account) and your recipient can read, forward, or reply to the message.
Internet e-mail addresses follow a certain convention, as follows:
username@host.sub-domain.domain.first-level domain
where username is the name of the account with the computer, host is the name of the computer that provides the Internet account, sub-domain is an optional internal designation, domain is the name assigned to the host organization's Internet presence, and first-level domain is the two- or three-letter code that identifies the type of organization that controls the host computer.
An example of a simple e-mail address (mine) is tstauffer@aol.com,
where tstauffer is the username, aol is the domain,
and com is the first-level-domain. com is
the three-letter code representing a commercial entity.
This e-mail address describes my account on the America Online
service, which is a commercial Internet site. (See Table 2.2 for
some of the more common first-level domain names.)
| First-level domain | Organization Type |
| .com | Commercial |
| .edu | Educational |
| .org | Organization/Association |
| .net | Computer Network |
| .gov | Government |
| .mil | Military Installation |
| .ca | Canadian |
| .fr | French |
| .au | Austrailian |
| .uk | United Kingdom |
| .jp | Japanese |
You may have also noticed that my address doesn't include a host name or a sub-domain. For this particular address, it is unnecessary because America Online handles all incoming Internet e-mail through a gateway. Once it receives the e-mail, it may indeed send it to another computer within its online service, but this is an internal operation that doesn't require a specified host in the Internet address.
Consider todd@lechery.isc.tamu.edu. This is an address
I had a few years ago when I worked at Texas A&M University.
(I no longer receive e-mail at this address.) Notice how it uses
all of the possible parts of an Internet address. todd
is the username, lechery is a host computer (in this case,
an actual, physical computer named "lechery"), isc
is a sub-domain name that represents the computers in the Institute
for Scientific Computation, tamu is the domain name for
all Internet-connected computers at Texas A&M University,
and edu is the three-letter code for educational,
which is the type of organization that Texas A&M is considered
to be on the Internet.
| When is a Host a Server? |
The Internet community uses the words host and server when talking about the type of computers you'll encounter. But what do these names mean? I like to use the analogy of a party. At a party, a host or hostess will welcome you into his or her home and point you to the various things you can do at the party. He or she will show you where to put your coat, point you to the refreshments, and tell you about their home. Now, depending on how large or lavish the party is, you may also have servers. Servers will perform more specific tasks, like bringing you beverages or food, opening the door, taking your coat, or moving furniture around. At a small party, the host may act as a server. At a larger party, the host will coordinate the servers. That's how hosts and servers work on the Internet. A host computer is generally a computer that allows its local users to gain access to Internet services. It may also allow other users to gain access to information in its organization. Depending on the size of the organization's Internet site, however, the host often doesn't serve that information itself. Instead, it relies on server computers that have more specific functions, like serving HTML documents, serving shareware programs, or serving UseNet news. These servers will be accessed through the host, though, so it's really only important to know the host's address on the Internet-just like in the real world. |
The next Internet service we'll talk about is UseNet newsgroups.
These are the discussion groups on the Internet, where people
gather to post messages and replies on thousands of topics ranging
from computing to popular entertainers, sports, dating, politics,
and classified advertising. UseNet is a very popular Internet
service, and most Web browsers have some built-in ability to read
UseNet discussion groups.
| Note |
Although you'll hear the word "news" a lot when you talk about UseNet, there isn't an overwhelming number of newsgroups that offer the kind of news you expect from a newspaper or CNN. In general, UseNet is comprised of discussion groups like the forums on CompuServe or the message areas on America Online. |
Like Internet e-mail, UseNet discussion groups have their own system of organization to help you find things. This system uses ideas and syntax that are similar to e-mail addresses, but you'll notice that UseNet doesn't require that you find specific hosts and servers on the Internet-just a particular group. UseNet newsgroup names use the following format:
first-level name.second-level.third.forth...
The first-level name indicates the type of UseNet group this is, the second narrows the subject a bit, and the address continues on until it more or less completely describes the group. For instance, the following are both examples of UseNet newsgroup addresses:
co.general
comp.sys.ibm.pc.misc
The first-level name co means this is a local UseNet group
for the Colorado area, and general shows that it's for
discussion of general topics. comp is a common first-level
name that suggests this is an internationally available newsgroup
about some sort of computing issue (see Table 2.3). The other
levels of the name tell you more about the group.
| First-Level Name | Description |
| alt | Alternative groups |
| biz | Business issues |
| clari | Clarinet news stories |
| comp | Computing topics |
| misc | Other general discussions |
| news | General news and help about UseNet |
| rec | Recreational topics |
| sci | Scientific discussions |
| soc | Social issues |
| talk | Debate-oriented groups |
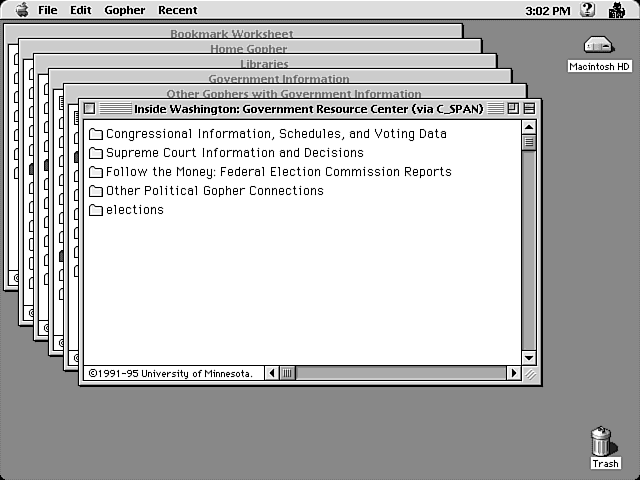
Gopher has been described as the poor man's Web, and it's definitely true that Gopher is a precursor to some of the Web's capabilities. Gopher is a system of menu items that link sites around the world for the purpose of information retrieval. This isn't a hypertext system like the Web, but it is similar to the Web in that it's designed for document retrieval (see fig. 2.8).
Figure 2.8 : Accessing Gopher menus with TurboGopher for Mac.
While Gopher can only offer access to text files and allow you to download files using the FTP protocol, it is still used occasionally by academic, government, and similar sites. Fortunately, your Web browser can easily offer Gopher access too, so there's no need to have a separate application.
WAIS, or Wide Area Information Servers, are basically database servers that allow you to search databases that are attached to Gopher menus. Library databases, academic phonebooks, and similar information are kept in WAIS systems.
Gopher and WAIS both generally require that you have the exact address of the Gopher server available to you. These addresses are in the following form:
host.sub-domain.domain.first-level domain
This works essentially like an e-mail address without a username. All the Gopher application needs to know is the exact Internet location of the Gopher server computer you'd like to talk to. An example might be marvel.loc.gov. This takes you to a Gopher menu for the Library of Congress.
The File Transfer Protocol (FTP) is the Internet service that allows computers to transfer binary files (programs and documents) across the Internet. This is the uploading/downloading protocol that you might use to obtain copies of shareware or freeware programs, or that might be useful for downloading new software drivers from a particular computer hardware company.
Using a model identical to the Gopher system, FTP addresses use the following format:
host.sub-domain.domain.first-level domain
Like Gopher addresses, an FTP address is simply the Internet address of a particular host computer. In fact, the same host address can be used to serve you both Gopher documents and FTP file directories, based on the type of protocol your access software requests. The following example is the FTP address for downloading support and driver files for Apple Macintosh computers and Apple-created Mac and Windows software:
ftp.support.apple.com
In most cases, FTP connections also require some sort of login
procedure, which means you'll need a username and password from
the system administrator to gain access. The majority of public
FTP sites, however, are anonymous sites, which allow anyone access
to their files. For these sites, the username is generally anonymous,
and you're asked to enter your e-mail address for the system's
password.
| Note |
Many Web browsers can access only anonymous FTP sites. You may still need a dedicated FTP program to access FTP sites that require an account username and password. |
The World Wide Web is the youngest and most unique of the Internet services. Its protocols allow it to transmit both text and multimedia file formats to users, while also enabling Web browsers to access other Internet services. The Web is based on a concept called hypertext, which means that text within the paragraphs on a Web page is designed to act as links to other Web pages. There is no hierarchy on the Web, which is only loosely organized by this system of links.
Other services that can be accessed via the Web include Gopher, WAIS, UseNet, e-mail, and FTP. Each of these older Internet services has its own scheme for formulating addresses. Most of these services require a server computer of some sort to allow Internet applications to access their information. These server computers have specific addresses on the Web which you need to know in order to contact them.